
 Abstract
Abstract
Embodied agents require robust and comprehensive 3D spatiotemporal representations to support spatial reasoning, manipulation understanding, and downstream decision making. However, existing robot data are typically captured from fixed or sparse viewpoints, providing only partial and view-dependent observations, which limits multi-view perception and generalization across viewpoints. Given the difficulty of collecting additional viewpoints in real-world settings, we propose Embody4D, a dedicated video-to-video world model for embodied scenarios to bridge this observation gap by transforming a monocular robot video into novel-view videos from flexible target camera viewpoints. First, to tackle training data scarcity, we introduce a 3D-aware compositional synthesis pipeline to curate a heterogeneous dataset compositing cross-embodiment robotic arms with diverse backgrounds, promoting broad generalization. Second, to enforce geometric stability, we devise a latent confidence-aware expert modulation strategy, which estimates the reliability of warped latent priors and adaptively routes regions to copy, repair, or inpaint experts for spatiotemporally consistent 4D generation. Finally, to enhance the fidelity of the manipulation, we incorporate an interaction-aware attention mechanism that explicitly attends to the robotic interaction regions. Extensive experiments show that Embody4D achieves state-of-the-art performance on visual evaluation benchmarks, while both simulated and real-world robotic experiments further demonstrate its effectiveness as a robust data engine for synthesizing high-fidelity, view-consistent videos that empower downstream robotic planning and learning.
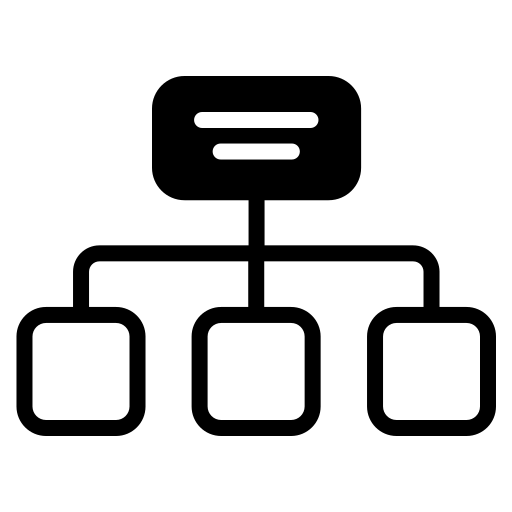 Framework Overview
Framework Overview
 Video Comparison Gallery
Video Comparison Gallery
A AGIBOT dual-arm robotic is performing a task with a toaster.
A Franka robotic arm engaging in a sorting or retrieval task on a dark tabletop.
A Universal robotic arm performing a block-sorting task on a wooden desk.
A LIFT2 dual-arm robotic performing manipulation tasks on a light-colored tabletop.
| VBench ↑ | MEt3R ↓ | |||||
|---|---|---|---|---|---|---|
| Method | Subject | Background | Temporal | Motion | Imaging | 3D Consistency |
| ReCamMaster | 0.8981 | 0.8976 | 0.9717 | 0.9841 | 0.5914 | 0.2454 |
| Ex-4D | 0.8088 | 0.8906 | 0.9213 | 0.9742 | 0.5732 | 0.2713 |
| Reangle-A-Video | 0.9152 | 0.9224 | 0.9711 | 0.9879 | 0.6437 | 0.2288 |
| TrajectoryCrafter | 0.9202 | 0.9388 | 0.9714 | 0.9911 | 0.6257 | 0.2040 |
| Ours | 0.9351 | 0.9491 | 0.9734 | 0.9937 | 0.6566 | 0.1681 |
 More Results Gallery
More Results Gallery
 Input
Input
 Embody4D
Embody4D
 Application
Application
For simulation experiments, we use Embody4D to generate view-randomized training videos, while evaluating policies from a fixed third-person camera. This setting isolates the effect of synthetic view augmentation on cross-view generalization and policy robustness.
For real-world experiments, we introduce an additional Embody4D-generated third-person view during training and inference. By expanding the observational coverage of robot-object interactions, this setting evaluates whether Embody4D can improve spatial reasoning, interaction understanding, and manipulation performance.



We evaluate π0.5 under LIBERO-Plus perturbation settings and compare training on the original LIBERO data with training using Embody4D-generated random-view samples and matched real multi-view data.

On LIBERO-Plus, the Camera score increases from 64.8% to 86.8%, indicating stronger viewpoint generalization.
*Recammaster is designed for controlling the lens movement of camera external parameters, making it difficult to achieve fixed-angle generation, which leads to inconsistent parallax and a decrease in the overall results.
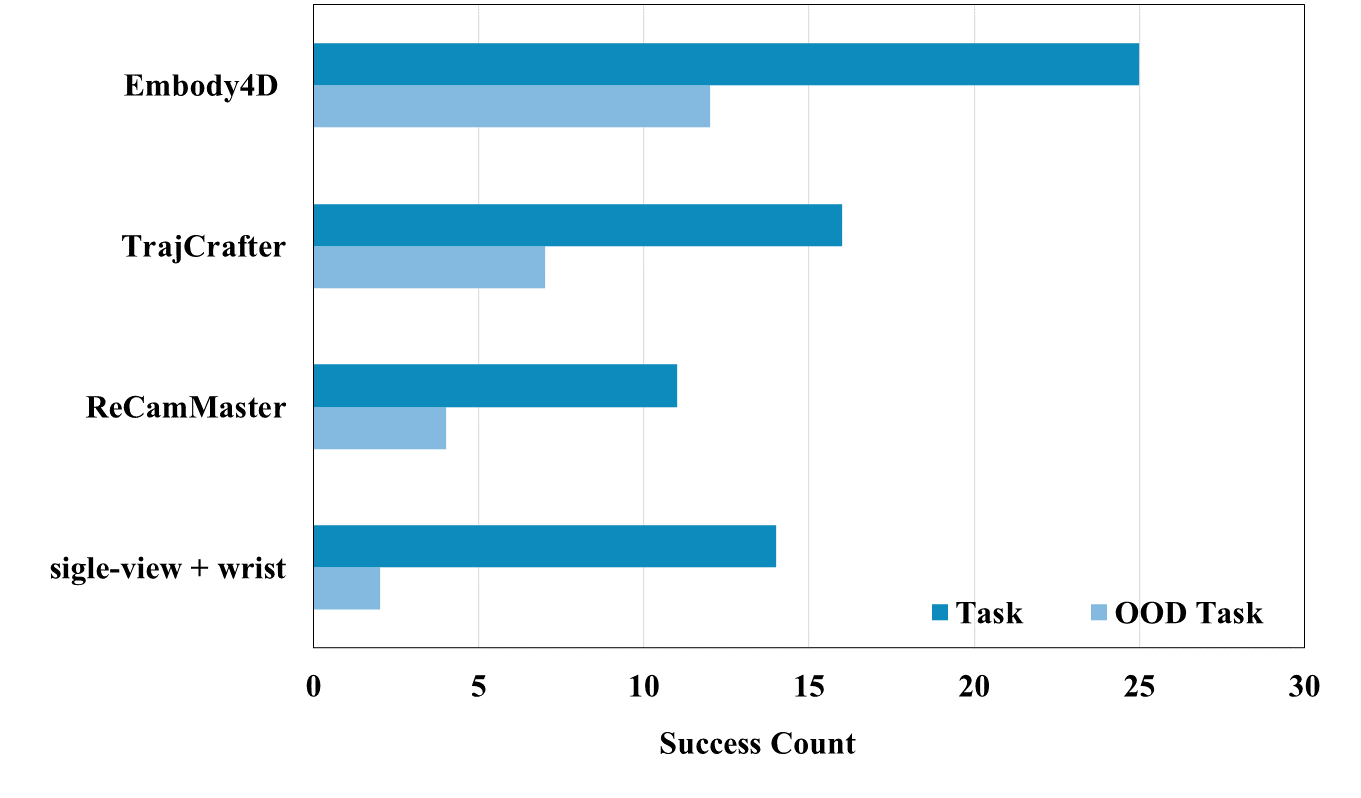
Embody4D acts as a scalable data engine for downstream robotic manipulation and planning. Leveraging its novel-view synthesis capability, the success rate of π0.5 improves dramatically from 32% to 74%, with particularly strong generalization to out-of-distribution (OOD) tasks.
| Baselines | Ours | |||
|---|---|---|---|---|
| Task | Single-view with wrist | ReCamMaster | TrajCrafter | Embody4D |
| T1 (Grapes→Bowl) | 5/10 | 4/10 | 6/10 | 8/10 |
| T2 (Grapes→Plate) | 5/10 | 5/10 | 6/10 | 8/10 |
| T3 (Mangoes→Bowl) | 4/10 | 2/10 | 4/10 | 9/10 |
| T4 (Lemons→Bowl unseen) | 1/10 | 2/10 | 0/10 | 6/10 |
| T5 (Bananas→Plate unseen) | 1/10 | 2/10 | 7/10 | 6/10 |
| Success Rate (SR) | 32% | 30% | 46% | 74% |
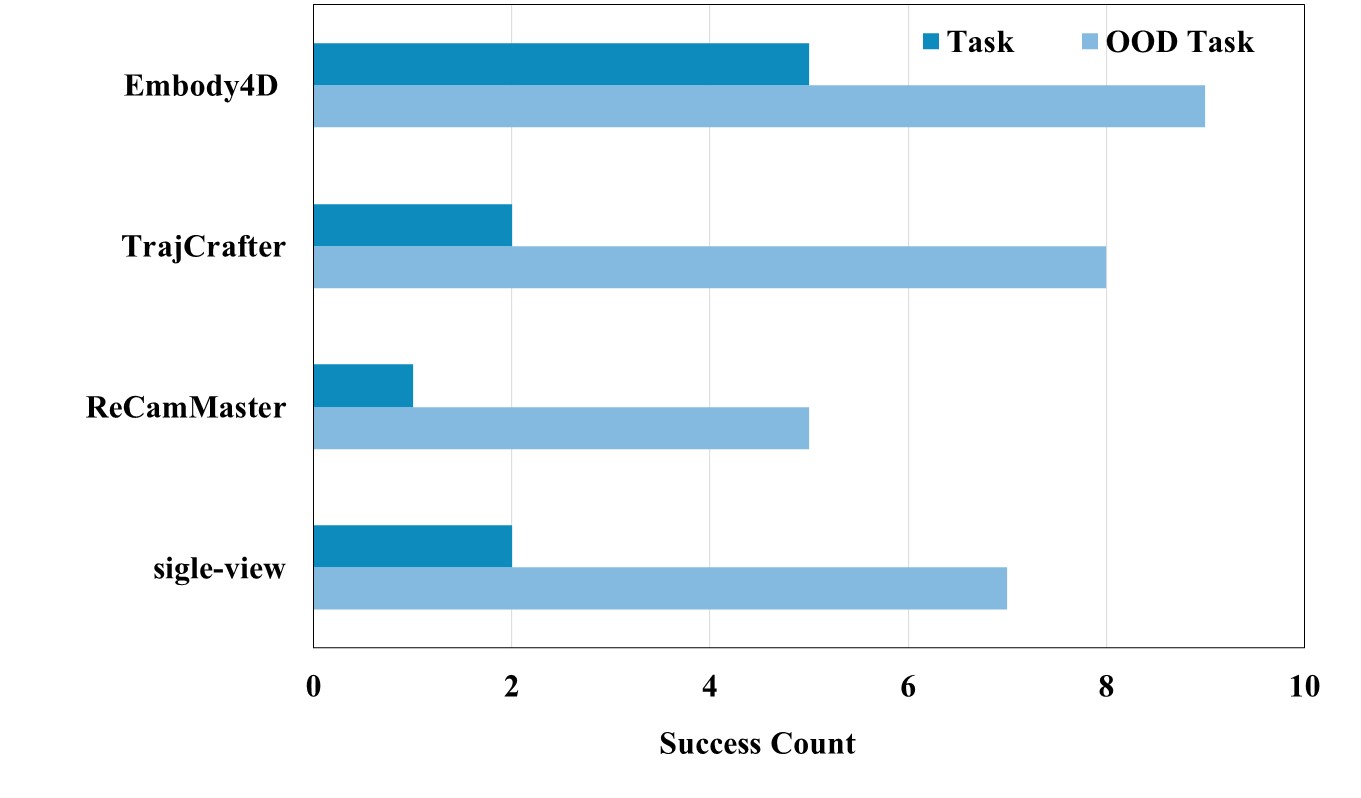
put the lemons from the table into the bowl
put the mangoes from the table into the bowl
